
---
config:
flowchart:
curve: "monotoneX"
layout: "elk"
elk:
nodePlacementStrategy: "NETWORK_SIMPLEX"
---
flowchart TD
A{What type of data?} --> B[Nominal / categorical]
A --> C[Continuous / numeric]
B --> D[Observed vs.
Expected]
B --> E[Relationship b/w
two variables]
D --> F(Chi-squared test
for goodness of fit):::terminal
E --> G(Chi-squared test for
independence):::terminal
C --> H[Comparison]
C --> I[Association]
I --> Cor(Correlation/
Regression):::terminal
H --> numgroups{How many samples
or groups?}
numgroups --> J[One]
numgroups --> K[Two]
numgroups --> L[More than
Two]
J --> numscores{"Num of scores<br />per subject"}
numscores --> M[One]
numscores --> N[Two]
numscores --> O[More than
Two]
M --> SD{Do you know the
population _SD_?}
SD --> P[Yes]
SD --> Q[No]
P --> z1(_z_-test for a
sample):::terminal
Q --> t1(_t_-test for a
single sample):::terminal
N --> t2(_t_-test for
dependent means):::terminal
O --> rm(Repeated-
measures ANOVA):::terminal
K --> independence{Matched or
independent?}
independence --> R[Matched]
independence --> S[Independent]
R --> t2
S --> t3(_t_-test for
independent means):::terminal
L --> independence2{Matched or
independent?}
independence2 --> T[Matched]
independence2 --> U[Independent]
T --> rm
U --> IVs{How many indep.
variables?}
IVs --> V[One]
V --> X(One-way<br />ANOVA):::terminal
IVs --> Z[Two]
Z --> Y(Factorial<br />ANOVA):::terminal
classDef terminal color:#FF0000,stroke:#FF0000,stroke-width:4px,font-weight:bold;
Objectives
Today’s lab’s objectives are to:
- Learn about independent-samples t-tests
- Learn how to conduct independent-samples t-tests in Jamovi (and, a little bit, with the help of Jamovi)
- Visualize the results of such tests
You’ll turn in an “answer sheet” on Brightspace. Please plan to turn that in by the beginning of the next lab.
Flow chart to decide on tests
Just as we discussed in class, here’s a flow chart that helps in making the decision about which test we’re doing. As you go through today’s assignment, think about whether it can be used. Additionally, consider reading “backwards” (from the bottom) for the tests we’ve done thus far. (Specifically, look at z-tests and the t-tests for single samples and independent samples.) For example, you’ll note that a z-test for a sample is used when we know the population SD, there is one score per subject, one sample (or group), and we are comparing continuous data (in this care, comparing it to a population mean). What do you notice about the other tests?
Independent-samples t-tests
We’re not going to learn how to calculate these in the step-by-step way—that’s in the homework, but not (mostly) today in lab.
But we will learn to do them with the Jamovi function, and to solve based on a known \(S^2_{pooled}\).
We’ll start by using the same friends data (still on Brightspace), although we’ll move onto real psychology examples very soon. Load the friends data into Jamovi.
Let’s look at the shootingdrills variable; I recoded it to have two meaningful values, which you should see under Data in Jamovi. We’ll have two groups here—those who had shooting drills and those who did not. But they’re not paired in any way, so it’s an independent-samples t-test. (Literally: these samples are independent from one another. We can ask “are the means different for each group?” But we can’t ask “how does this group’s mean change?” because they’re not related.) You can go back and look at the flow chart to think through this: the t-test for independent means is used when we have two, independent groups, for which we are comparing their continuous (numeric) data.
We can look at this shootingdrills variable relating to the numeric response asking respondents about how many students were in their high school, hs_students. Nothing exciting, but could be interesting. We can ask: are those who had shooting drills more likely to have had larger high schools?
We started with 67 observations (respondents) here, and of those there are only 10 respondents who did not have shooting drills and 41 who did. Some people didn’t respond to this question, and there are uneven groups. Nonetheless! We can do a t-test, even if I would be wary normally of doing a t-test with such uneven groups.
Let’s quickly review the steps of hypothesis testing as they pertain to an independent-samples t-test:
What are the null and research hypotheses? (click to expand)
Either the means of the groups are equal (the null):
\[H_0: \mu_{\textrm{had shooting drills}}=\mu_{\textrm{didn't have shooting drills}}\]
Or they are different (the research hypothesis):
\[H_1: \mu_{\textrm{had shooting drills}}\neq{}\mu_{\textrm{didn't have shooting drills}}\]
Step 2 is to describe the comparison distribution. Although you don’t know its standard deviation, what do you know about the comparison distribution for a t-test for independent means?
Describe the comparison distribution (click to expand)
It is the distribution of the differences between the means for our two groups, so it has \(\mu_{difference}=0\). It’s going to be a t-shaped distribution based on the degrees of freedom for both groups, combined, which is somewhere \(\le 65\). (There are 67 respondents to the friends dataset, so at minimum it’s \(n-1\). In this case, it’s actually going to be \(df=49\).)
I can also tell you that the \(S_{difference}\) in this case is \(\approx 12.28\); we can say that the standard deviation of this comparison distribution is about 12.28. Of course, once we convert it to a t-distribution, we’re dividing by that value. It’s just the thing we’re basing our distribution on.
The t-distribution with \(df=49\) looks just about like this:
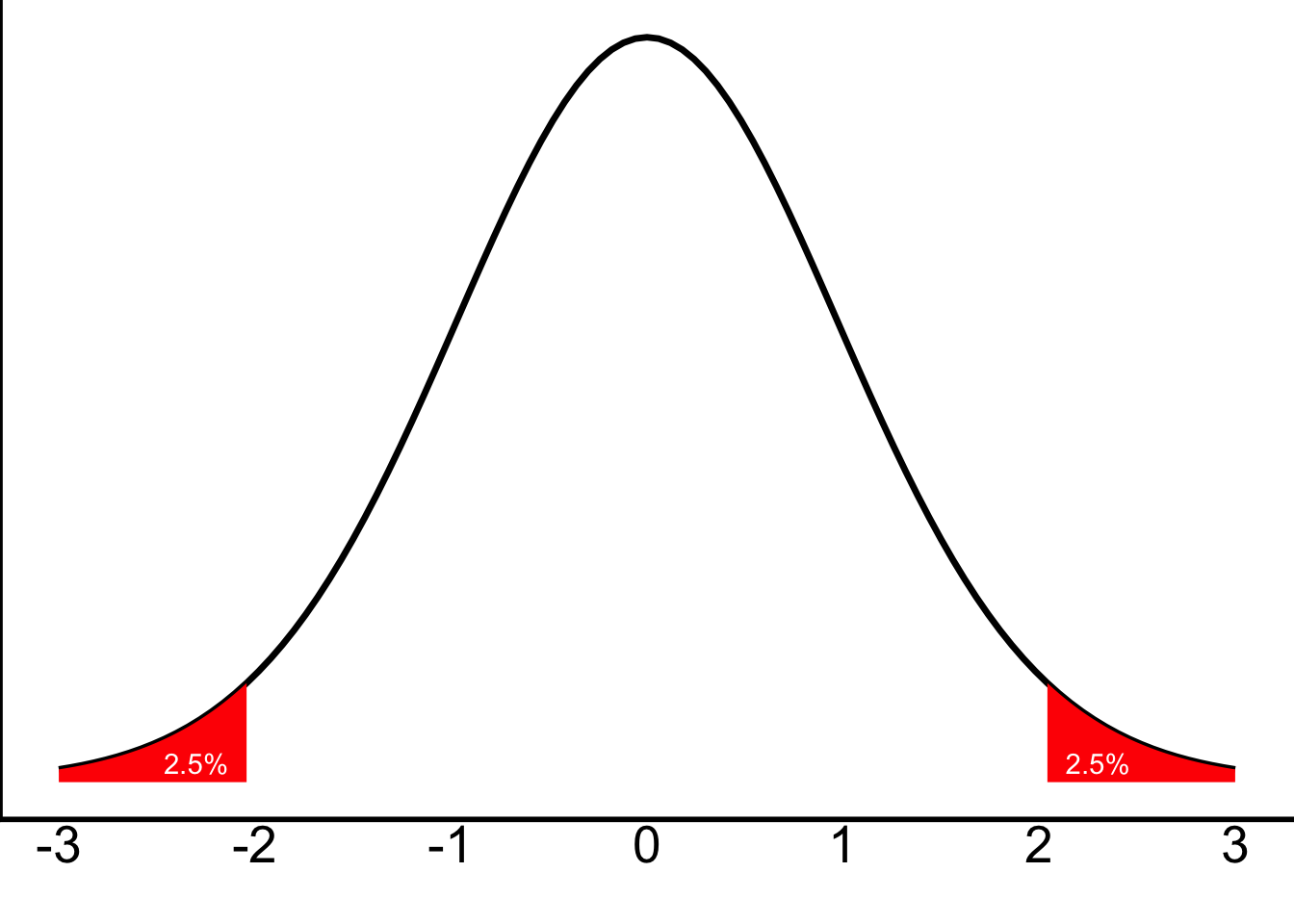
Step 3 is to determine the cutoff values for rejecting the null hypothesis. Use a t-table (or the app that we discussed last lab) to look up the cutoff values for a two-tailed test when we’re asking is \(p<.05\) and have the \(df\) we discussed in the answer above.
What are the cutoff values?
Looking at a t-table should give you about \(t_{crit}(49)=\pm2.01\)—recall that you round down your \(df\) if needed for the table.
We can add them onto the plot:
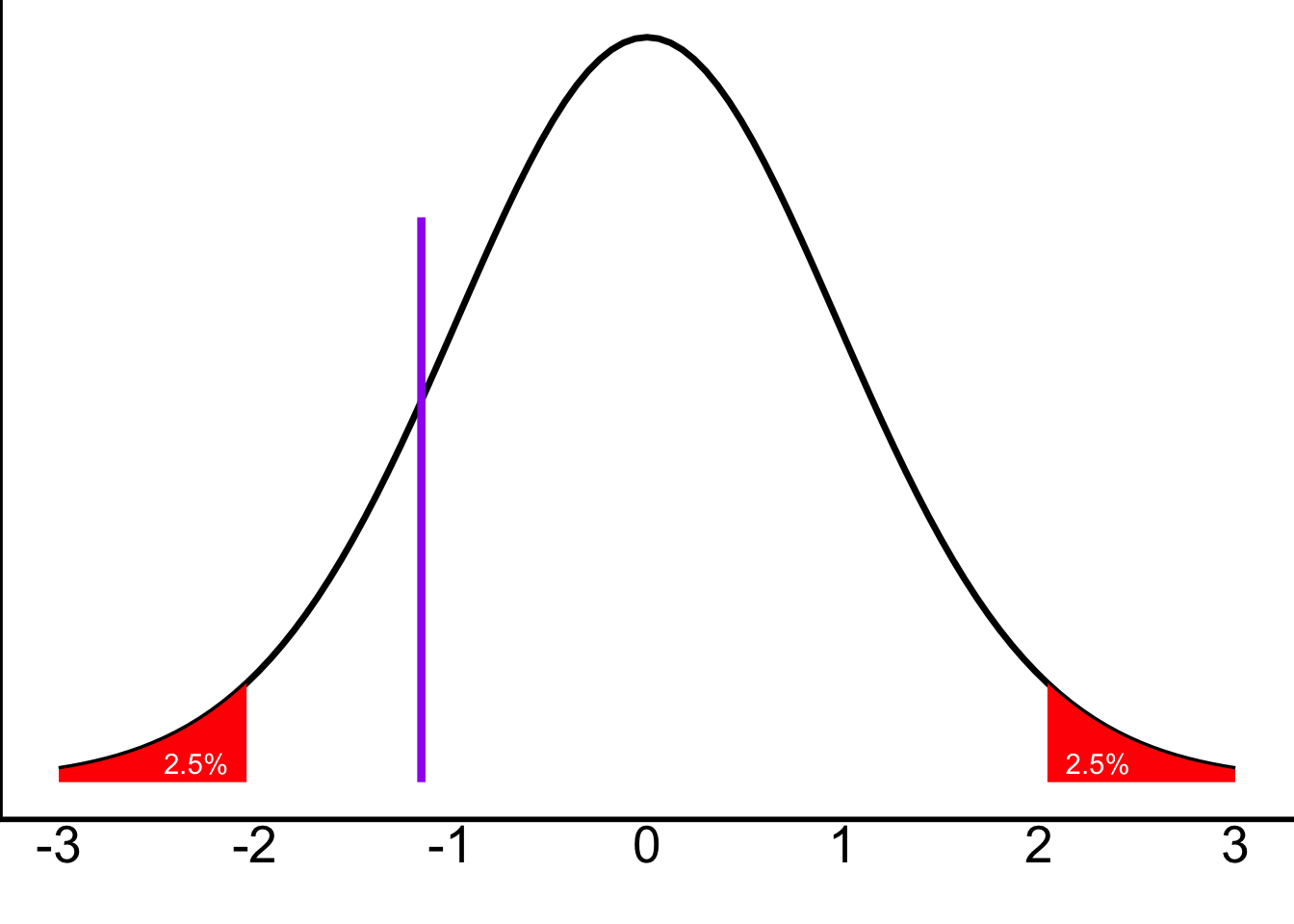
For step 4 (finding the t-score) and step 5 (comparing it to those cutoff values), we can just do this in Jamovi. (Remember, Jamovi doesn’t give you the critical t-value—it gives you a p-value, which answers the question in step 5 for you.) This is why we don’t usually report the \(t_{crit}\)—it’s usually easier to just report the results of step 5.
In Jamovi, click on Analyses, T-Tests, Independent Samples T-Test. Put shootingdrills into the Grouping Variable and hs_students into the Dependent Variable. Make sure Student’s t is selected.
Look over the results in Jamovi. Click below to see what your results should look like.
See the results and discuss what they mean (click to expand)
| Independent Samples T-Test | ||||
|---|---|---|---|---|
| Statistic | df | p | ||
| hs_students | Student's t | 0.53 | 49.0 | 0.600 |
The “Statistic” is the t-value. Here, it’s 0.53: positive, because our groups are ordered such that Jamovi subtracted a smaller number from a larger one. We also have the df, which we found above. And Jamovi gives us a p-value for the t-statistic. Again: it’s not the \(t_{crit}\). It’s the actual p-value that your t corresponds to. So when \(t=0.53\) for \(df=49\), Jamovi has looked up that it corresponds to a p-value under the null of 0.600. Your task is just to ask “is this p smaller than the p I was asking about, which here is 0.05?” And no, 0.600 is not smaller than 0.05.
You can also click “Descriptives” under the T-Test menu in Jamovi, and it will give you the means of each group. This is often useful. Try it now.
Practice writing up the results. Include the means of each group, whether the results are significant, and the results of the t-test. You should follow what I have below in your answers for most of the questions today! We already started doing this last lab.
Practice writing the results as we discussed in class and last lab, then click here to see my answer and a discussion.
There was no significant difference between groups. The shooting drills group (\(M = 1163.9\)) showed no significant difference from the no-drills group (\(M = 1390\)) in terms of how many students they had in their schools, \(t(49)=0.53,p=0.60\).
You could also write \(p>.05\). Generally speaking, the point of these tests are to ask “is \(p<.05\)?” And so I think you should often just answer that question with either “yes” or “no”, and not answer some other question. That said, and as I said last lab, we are more likely to report the exact p-value when the test was not statistically significant, and it is not significant here.
Those means are still somewhat far apart! But the groups are very different in size, and the standard deviation of the comparison distribution was quite large as we discussed above. So even a large difference doesn’t mean much when the standard deviation is also large.
We can add that _t_score into the plot from above:
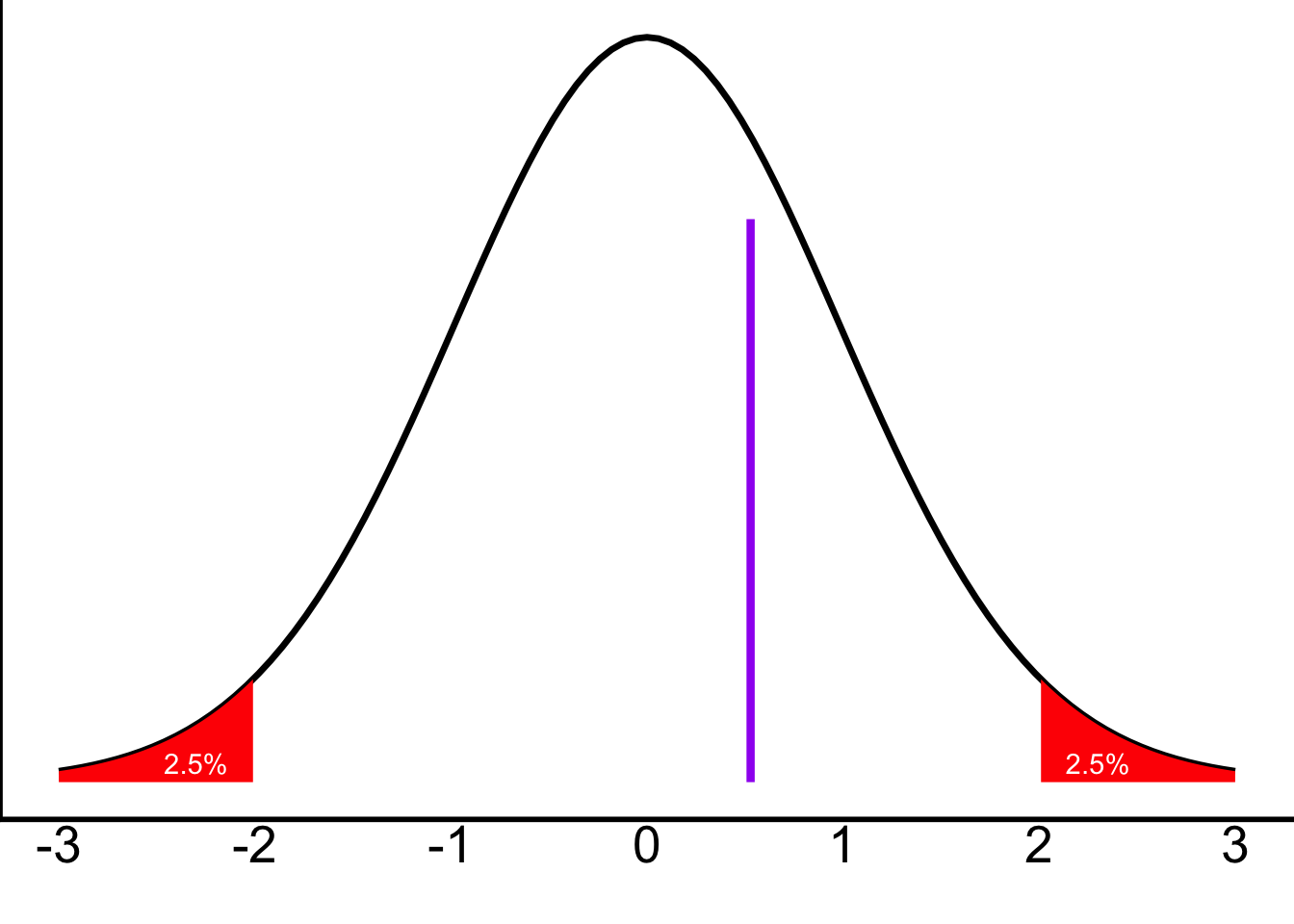
Visually, you should be able to see that this score falls within the null distribution; it isn’t extreme. Therefore, it makes sense that we have failed to reject the null.
Okay, now do these on your own.
With the
friendsdata, use thecigarettescolumn (whether or not they’re a smoker) and thelike.dancecolumn (how much they like to dance). Is smoking a predictor of how much people like to dance? Use an independent-samples t-test. Write up your results. Use the steps of hypothesis-testing if that’s helpful. The important things to turn in for #1 are the results of the test and an answer to the question. Write up the results. (Not sure what I mean by “write up the results”? Do it like I did in the dropdown that says “Practice writing the results”. Report the groups compared, their means, the direction of the effect, and the results of the t-test.)Do cigarette smokers travel a different amount from those who don’t smoke? Use variables
cigarettesandcountries(how many countries they report having been to). Changecountriesto be a continuous variable in Jamovi. Don’t remove any outliers—I’d say 25 is a possible response. For #2, report the results of the test.You can create a bar plot in Jamovi. Under Analyses, click on Exploration, then Descriptives. Put
countriesin Variables andcigarettesin the Split By section. Under plots, turn on the Bar plot. Also include this plot in #2.Are people with “natural” hair color more likely to come from smaller schools than those with dyed hair? Use variables
haircolorandhs_students. Write up the results, including the means and t-test, as #3. (And yes, use a two-tailed test here. Always default to the two-tailed test!)Go to the data tab and scroll to the column
operasin the data—how many operas our sample has seen. With it selected, click Transform in the ribbon. Name the new columnoperaYN. Where it says “using transform”, select the dropdown where it says None and switch it to Create New Transform. Click + Add New Recode Condition twice. Your first recode condition should readif $source == 0 use "no"and your second one should readif $source > 0 use "yes"; below it will readelse use $source. What does this mean? It means thatoperaYNnow reads “yes” for folks who have seen any number of operas, “no” for those who have never seen an opera, and is blank for everyone else. Now, use an independent samples t-test to determine whether people who have seen an opera (usingoperaYNas the grouping variable) watch tv more/less than those who do not (using thetvhoursvariable as the dependent variable). Write up your answer as #4. There are several possibly-outlying values, but don’t remove them.Now, let’s look at the Schroeder & Epley (2015) data we discussed in class. Download it here or on Brightspace and load it into Jamovi. Re-run the test we discussed in class: does
CONDITIONpredictHire_Rating? (CONDITIONis 1 and 0; 1 corresponds to Audio and 0 to Transcript.) Your resulting t-value will be negative. What does that mean? Answer this question, and include the t-test results, for #5. Then, try using the variable (lowercase)conditioninstead. It just has the CONDITION variable recoded to be a bit more meaningful. Why do you think the t is switched from negative to positive?
Repeat the test with the
Intellect_Ratingvariable instead. Use the lowercaseconditionvariable from here on out. Write up the results for #6.Okay, now some quick practice for the exam. I’ll provide some numbers: the means for impression rating by groups are \(M=5.97\) for the audio group and \(M=4.07\) for the transcription group, the sample sizes are (as we discussed in class) \(n_1=21\) for the audio group and \(n_2=18\) for the transcription group, and the pooled variance is \(S_{\textrm{pooled}}^2=4.28\). Use those numbers and the formulae below this paragraph to calculate \(S_{\textrm{difference}}\) and t. As #7, report the standard deviation of the distribution of the difference between the means (\(S_{\textrm{difference}}\)). Then report the results of the t-test. You should practice using a t-table, but can use the Probability Distributions app or run this test (with the
Impression_Ratingvariable) in Jamovi to confirm your t-value and your conclusion.Remember that the \(S_{\textrm{difference}}\) is the standard deviation of the distribution of the differences between means, the \(S_{\textrm{pooled}}^2\) is the pooled variance, and 1 and 2 refer to the samples:
\[S_{\textrm{difference}}=\mathit{SE}=\sqrt{S_{\textrm{pooled}}^2(\frac{1}{n_1}+\frac{1}{n_2})}~~\textrm{and}~~t=\frac{M_1-M_2}{S_{\mathrm{difference}}}\]
- Finally, create a graph representing the results of at least one of these tests. Use Excel or Google Sheets, or get Jamovi to present the results in a way that makes sense. This is answer #8. Your graph should have labeled axes and include error bars (you could use SEM by group or the \(S_{difference}\) for error).
Reuse
Citation
BibTeX citation:
@online{dainer-best2025,
author = {Dainer-Best, Justin},
title = {\_T\_-Tests for Independent Means {(Lab} 6)},
date = {2025-10-09},
url = {https://faculty.bard.edu/jdainerbest/stats/labs/posts/06-t-tests/},
langid = {en}
}
For attribution, please cite this work as:
Dainer-Best, Justin. 2025. “_T_-Tests for Independent Means (Lab
6).” October 9, 2025. https://faculty.bard.edu/jdainerbest/stats/labs/posts/06-t-tests/.